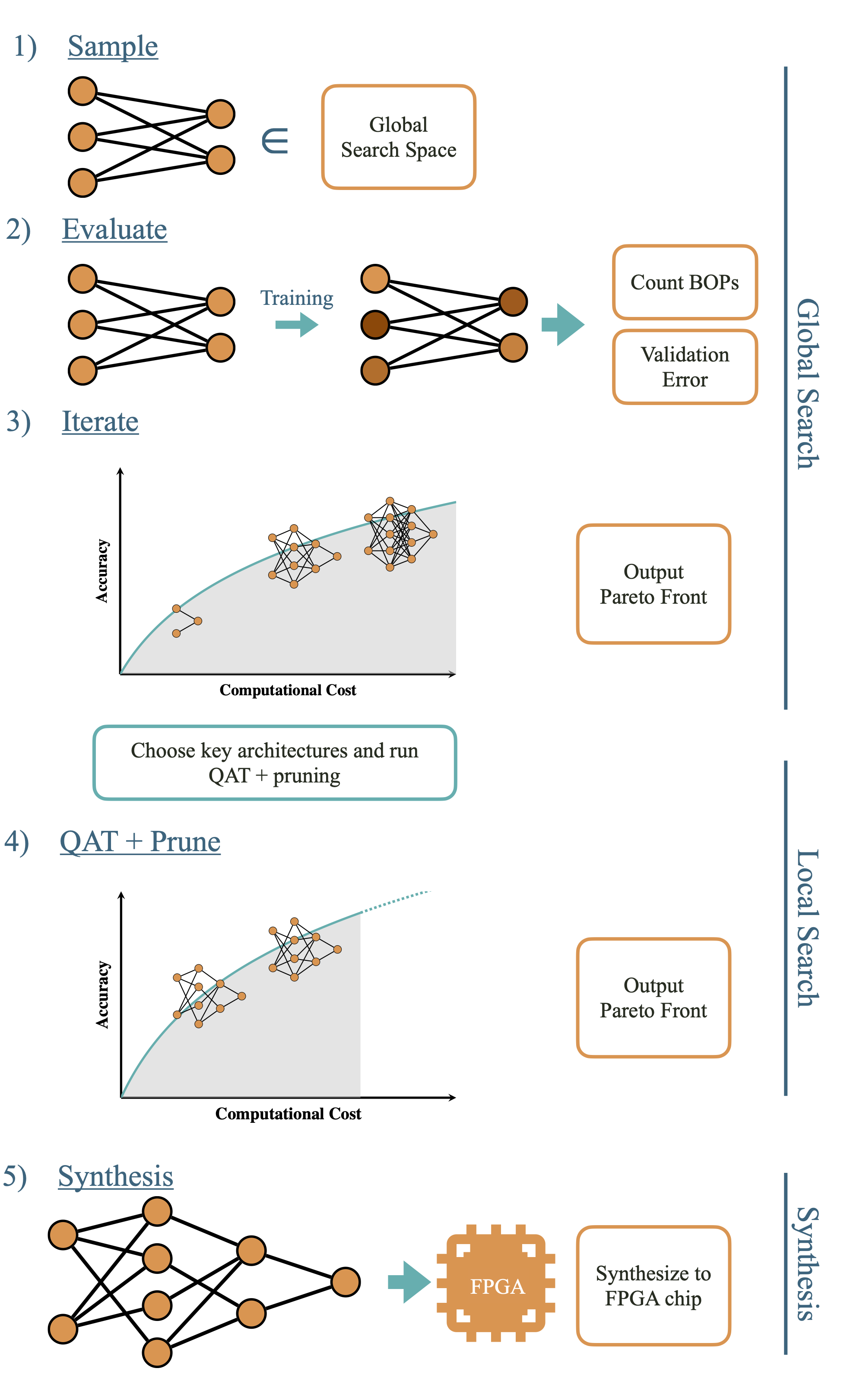
Morph Neural Architecture Search Pipeline
We create a plug-and-play pipeline called Morph that leverages block-based neural network layers to perform Neural Architecture Search, discovering the optimal model architecture for any given task. The pipeline then applies quantization and pruning techniques to generate a Pareto curve, allowing users to select the model that best meets their specific requirements. This approach is specifically tailored for deployment on CPUs and FPGAs.
Our automated pipeline streamlines the neural architecture codesign process for physics applications. By incorporating hardware costs into our neural architecture search methodology, we discover more hardware-efficient neural architectures. Our approach not only surpasses existing performance benchmarks across various tasks but also achieves additional speedup through model compression techniques, including quantization-aware-training and neural network pruning. We transform these optimal models into high-level synthesis code for FPGA deployment using the hls4ml library. Furthermore, our hierarchical search space provides enhanced optimization flexibility, making it readily adaptable to different tasks and domains.
We demonstrate the effectiveness of our approach through two detailed case studies: Bragg peak finding in materials science and jet classification in high energy physics.
This ongoing project is being conducted in collaboration with Javier Duarte. We have published our initial findings in a paper that can be accessed here. For a more comprehensive overview of our work, please refer to the Publications section.